

Les risques liés à l'utilisation du Big Data
Malgré (ou peut-être à cause de !) ma formation technique, mon objectif pour la version AI était de développer du matériel lié à l'éthique et aux effets de l'automatisation croissante dans le monde. Il est essentiel qu'en tant qu'individus, nous puissions être des "citoyens informés" et mon idée était (et est toujours) d'avoir un cours dédié à donner aux étudiants une compréhension de base des avantages et des inconvénients des différents événements actuels. L'un des principaux objectifs d'apprentissage du cours serait de définir suffisamment de termes de vocabulaire pour que les étudiants soient capables, par exemple, d'analyser de manière critique le contenu d'un article de journal ou de magazine.
Cela dit, la plupart de ces sujets peuvent également être présentés de manière isolée ou dans le cadre d'autres cours. Vous trouverez ci-dessous quelques-unes des ressources que j'ai développées pour aider les enseignants à présenter ce matériel. J'imagine que ces ressources pourraient être utiles dans certains cours existants tels que le 420-BWC (Introduction à l'informatique), le 420-BXC (Introduction à la programmation) ou un cours d'éthique tel que le 345-BXH (Éthique appliquée). Elles peuvent également être présentées dans de nombreux cours du département d'informatique comme des leçons liées à l'importance de poser des questions critiques sur la façon dont son travail sera utilisé dans la pratique.
Ressources
Il s'agit probablement du module le plus important, car il permet de comprendre les limites du big data. Nous ne devrions pas nous contenter de "jeter les données dans un algorithme d'apprentissage automatique et de voir ce qu'il en ressort". C'est extrêmement dangereux pour plusieurs raisons. Tout d'abord, cela peut aboutir à des conclusions injustes, biaisées et discriminatoires qui ciblent injustement des groupes. Ces groupes sont généralement les mêmes que ceux qui sont déjà sous-représentés dans de nombreux endroits et les algorithmes d'apprentissage automatique, lorsqu'ils sont appliqués de manière inconsidérée, ne font qu'exacerber cette situation.
Pour comprendre cela, nous devons considérer que même si des données peuvent étayer une affirmation, il y a souvent des raisons sous-jacentes (variables cachées) qui conduisent aux résultats. C'est l'idée de "corrélation vs causalité". Un exemple est donné dans les diapositives : Il s'avère que les ventes de glaces et les attaques de requins se produisent en même temps (en raison, bien sûr, de la variable cachée "été"). Il serait erroné de conclure que, puisqu'ils se produisent en même temps, nous devrions interdire les ventes de glaces pour réduire les attaques de requins. Un autre exemple célèbre est l'affirmation selon laquelle les pirates ont empêché le réchauffement de la planète (voir le graphique ci-dessous).
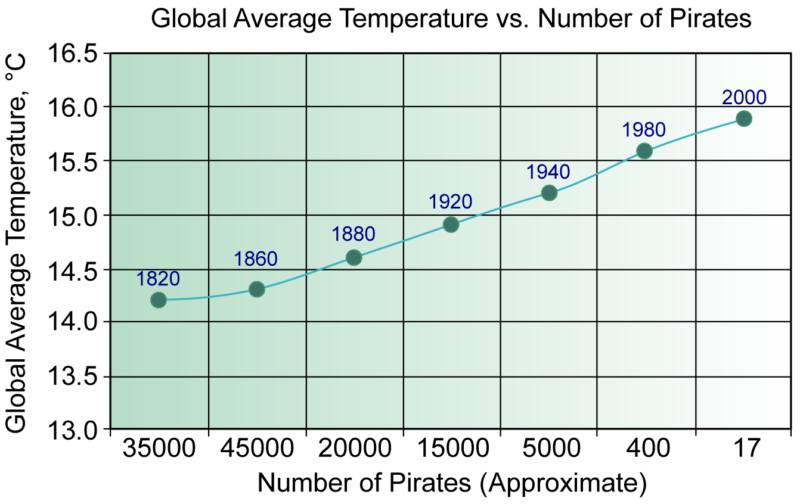
À l'époque où il y avait plus de pirates sur Terre, la température globale était moins élevée. Mais il ne s'agit évidemment pas d'une question de causalité. C'est pourquoi nous devrions toujours chercher à expliquer ces phénomènes de données et ne pas nous contenter de "faire confiance aux données".
En outre, il existe un risque de "p-hacking" qui résulte du concept de "statistiquement significatif". En général, nous disons que les résultats sont "statistiquement significatifs" si nous pensons qu'ils ne se produiraient par hasard que dans 5 % des cas. Par exemple, dans les études médicales, les participants sont divisés en deux groupes : un groupe de contrôle qui reçoit une pilule placebo et un groupe qui reçoit le médicament. Si le groupe recevant la vraie pilule obtient des résultats améliorés (par rapport au groupe de contrôle) qui ne se produiraient que dans 5 % des cas si la pilule n'avait aucun effet, on conclura que les résultats sont statistiquement significatifs et que la pilule est utile.
Essentiellement, ce que cela peut signifier, c'est que si vous testez 1000 hypothèses différentes, certaines d'entre elles seront inévitablement vraies par accident. Si quelque chose a 5 % de chances de se produire et que vous l'essayez 1000 fois, cela se produira certainement plusieurs fois. Pour en savoir plus sur le p-hacking, veuillez consulter le lien suivant : https://fivethirtyeight.com/features/science-isnt-broken/#part1
Dans cette série de diapositives, il est question du terme "Big Brother" en tant que terme de remplacement pour "surveillance" et de l'idée que tout ce que nous faisons est stocké. Quelles sont les obligations des entreprises privées telles que Google en matière de protection de la vie privée ? Qu'en est-il des fournisseurs d'accès à Internet ? Devraient-ils être tenus d'effacer nos historiques web après un certain temps ?
Le suivi des données a quelques utilisations positives ; Google a développé une application appelée "Google Flu Trends" (qui a été supprimée par la suite). L'idée était de prévenir la propagation d'une maladie en identifiant rapidement des tendances telles qu'une augmentation des requêtes de recherche suggérant des maladies (par exemple, "un degré au-dessus de la normale est-il de la fièvre ?"). Mais à qui appartiennent ces données ? S'il est facile de dire que les entreprises privées ne devraient pas les détenir, les grands gouvernements posent également problème. (En fait, l'expression "Big Brother" désignait à l'origine le gouvernement).
Cette série de diapositives (plus courte) aborde certains des avantages et inconvénients de la reconnaissance faciale. L'utilisation de la reconnaissance faciale présente certains avantages, par exemple pour attraper les "criminels". Mais ces avantages s'accompagnent de risques énormes (État policier, publicité constante). Une autre question qui n'est pas mentionnée dans les diapositives est la suivante : "Les parents devraient-ils être autorisés à publier des photos de leurs enfants sur les médias sociaux ? C'est ce qui se fait, sans le consentement de leurs enfants (qui ne peuvent pas donner un consentement éclairé). Ces photos peuvent ensuite être utilisées par de futurs algorithmes (qui seront sans aucun doute meilleurs que les algorithmes actuels) pour identifier leurs enfants de nombreuses façons.
Systèmes de génération de texte:
Ce diaporama était la première partie d'une présentation donnée à Dawson journées pédagogiques en 2020. Il donne un aperçu de l'histoire des systèmes de génération de texte au fur et à mesure de leur évolution, depuis les premières générations jusqu'à celles d'aujourd'hui, capables d'écrire des textes très avancés et détaillés. Cette conférence aborde également une notion importante en IA appelée le « test de Turing » du nom d'Alan Turing. L'idée est qu'un système d'IA est considéré comme réussissant le test si un utilisateur du système ne peut pas déterminer si le système est une IA ou un humain.
Test de Turing :
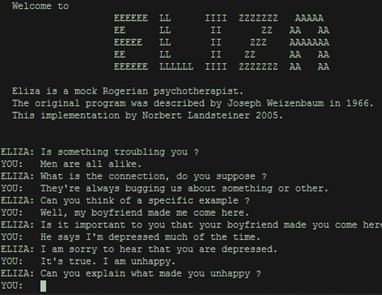
Voici une conversation amusante entre Eliza, un chatbot imitant un psychologue, conçu dans les années 1960 au MIT, et un humain. Le chatbot a été conçu pour suivre un script.
Autres liens intéressants
Voici d'autres liens intéressants, en rapport avec l'intelligence artificielle.
Comment programmer des voitures autopilotées ? En tant que conducteurs de voitures, nous prenons souvent des "décisions" en une fraction de seconde. Si une voiture s'arrête devant nous et que nous faisons un écart pour l'éviter, mais que nous heurtons quelqu'un d'autre au passage, nous considérons normalement qu'il s'agit d'un "réflexe" (d'où le terme d'"accident"). Cependant, dans la conception des voitures autonomes, nous sommes obligés de programmer ces choix à l'avance. La vidéo aborde certaines ramifications de ce phénomène. Les chercheurs présentés dans cette vidéo ont également mené une vaste enquête auprès de personnes du monde entier afin de comprendre leurs choix personnels dans ces situations. Bien que les données soient intéressantes, elles soulèvent la question très importante suivante : "Voulons-nous vraiment déterminer notre morale sur la base des règles de la majorité ?" Ce type de "raisonnement" a été à l'origine de nombreuses atrocités historiques parmi les plus graves au monde.
Deep-blue contre Kasparov: Il s'agit d'un résumé intéressant du célèbre match d'échecs de 1996 entre Deep Blue d'IBM et Garry Kasparov, le champion du monde d'échecs de l'époque. Ce match m'a personnellement intéressé et m'a poussé à m'intéresser à l'intelligence artificielle parce que je joue aux échecs en compétition. Il est intéressant de noter qu'à l'époque, le principal avantage de l'ordinateur était d'ordre psychologique : il ne se fatiguait pas ! Les ordinateurs d'aujourd'hui (comme Alpha-Go) sont tellement plus puissants qu'il n'y a tout simplement pas de compétition aux échecs entre "l'homme et la machine".
Présentation initiale: Voici une présentation que j'ai faite lors d'une des réunions de la communauté de pratique de Dawson sur le thème de l'IA. Elle est incluse ici par souci d'exhaustivité et de contexte. Au cours de cette présentation, j'ai discuté de mes objectifs pour la version

