

Exploration de l'apprentissage automatique sur une grappe de l'Internet des objets
Aperçu
Ma proposition pour la communauté de pratique était d'explorer l'apprentissage machine (ML) sur un cluster de périphérie IoT (Internet des objets). En bref, au lieu d'utiliser la puissance de l'informatique en nuage pour former des modèles d'apprentissage automatique, nous utilisons de minuscules appareils qui consomment moins de ressources pour effectuer la formation. Les véritables percées dans l'utilisation et la recherche en IA/ML ont été rendues possibles par les ressources collectives et la puissance de l'informatique en nuage. Avant la généralisation de l'informatique en nuage, nous n'avions pas la capacité d'aller de l'avant, ce qui explique que l'IA/ML soit un phénomène relativement récent. En raison des limites de l'utilisation de l'informatique en nuage, la formation à la périphérie est explorée comme un moyen de renforcer l'intelligence artificielle.
Mes expériences m'ont conduit dans une direction légèrement différente de celle à laquelle je m'attendais. Il sera peut-être possible d'explorer mon hypothèse de départ à l'avenir, mais les contraintes de temps et d'équipement m'ont fait comprendre que pour obtenir des résultats convenant à un étudiant en informatique, je devais changer de cap.
En expérimentant avec quelques Raspberry Pis, j'ai créé quelques diapositives de base et quelques dépôts de code, dont voici un résumé. Les diapositives ont été rédigées à l'intention d'un public d'étudiants en informatique.
Informations générales
J'ai commencé ce site dans le cadre de mon projet et j'y travaille encore. J'espère qu'il fournira des définitions plus claires de la terminologie dans un endroit central : AI & ML en langage clair.
Contexte
Le premier jeu de diapositives que j'ai créé avait pour but de faire comprendre aux étudiants ce qu'est l'informatique en périphérie : il donne un aperçu de ce que signifie l'informatique en périphérie, de ce que l'on peut y faire et de la raison pour laquelle nous avons besoin des ML pour la prise de décision.
01 conférence edge computing - modèle
Le deuxième jeu de diapositives présente quelques idées fondamentales sur l'apprentissage automatique. Il s'agit d'une vue d'ensemble des concepts de haut niveau, y compris l'opposition entre l'apprentissage à la marge et l'utilisation d'un modèle pré-entraîné.
02 conférence : Qu'est-ce que l'apprentissage automatique ?
Algorithmes, ML et formation
Les étudiants en informatique écrivent des algorithmes dès leurs premiers cours et tout au long du programme. Le prochain jeu de diapositives présente les idées avec lesquelles ils ont travaillé en créant leurs propres algorithmes afin d'illustrer le besoin de ML à mesure que la complexité augmente et que les facteurs de données augmentent.
03 cours sur les algorithmes d'apprentissage automatique - modèle
Le dernier jeu de diapositives présente les idées qui sous-tendent la formation des algorithmes de ML à l'aide d'un exemple introductif simple utilisant quelques algorithmes courants tels qu'une régression linéaire très simplifiée, les K plus proches voisins et un réseau neuronal. Vous trouverez ci-dessous des liens vers les dépôts où le code est disponible.
04 lecture formation d'un algorithme ML - modèle
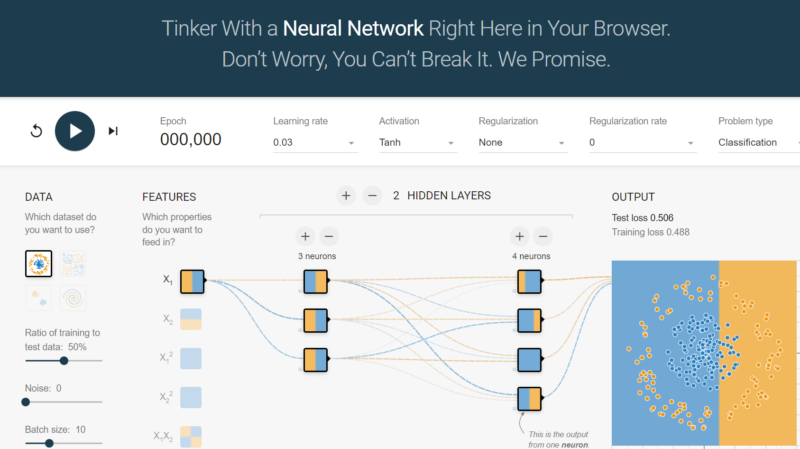
Essayez l'aire de jeu du réseau neuronal Tensorflow
Code
Dans le cadre de mon exploration de ce sujet, j'ai travaillé avec du code pour illustrer quelques-uns des algorithmes de ML les plus simples et leur formation afin d'initier en douceur les étudiants ayant une formation en programmation aux concepts de ML. L'ensemble du référentiel, auquel il est fait référence dans le diaporama 04, peut être consulté ici : https://github.com/campbe13/experiment-ml-docker-py/
kNN
Scikit Learn : kNN
J'utilise 1 csv pour m'entraîner, 2 mon propre jeu de données, 3 python classique :
https://github.com/campbe13/experiment-ml-docker-py/tree/master/00temperature-example
Régression linéaire
SciKit Learn : Régression linéaire
Utilisation 1. Générer un jeu de données et des résultats pour s'entraîner 2. un bon vieux python (3 des deux précédents avec le timing) :
https://github.com/campbe13/experiment-ml-docker-py/tree/master/05algebraeic-example
Réseau neuronal
DIY NN (utilisant NumPy & Matplotlib pour le graphique d'erreur) :
https://github.com/campbe13/experiment-ml-docker-py/tree/master/10neural-net
Utilisation de Raspberry Pis et Edge Impulse
Comme je l'ai mentionné, je voulais initialement effectuer l'apprentissage du modèle à la périphérie. J'ai commencé par mettre en place un cluster pour tenter un apprentissage fédéré, mais je n'ai pas réussi. Malheureusement, les contraintes de temps et d'équipement m'ont fait comprendre que pour obtenir des résultats convenant à un étudiant en informatique, je devais changer de cap. C'est alors que je me suis tourné vers Edge impulse.
Voici une base pour un laboratoire et un journal de la possession utilisée : engr log edge-impulse
Support du laboratoire : instrs - lab - setup Raspberry PI also edge training data github
Résumé
Tous mes travaux publiés ici peuvent être utilisés comme matériel de base, ils sont tous sous licence (sauf indication contraire). Mon propre travail écrit est sous licence CC BY-NC-SA 4.0. Mon propre code est sous licence MIT (The MIT License).
Comme toujours, il y a plus à apprendre et plus à ajuster pour l'étudiant du CEGEP en fonction du niveau des étudiants et du cours, mais considérez cela comme un travail en cours ! Toute erreur ou omission est de mon fait.

